Why do LLMs love corrective juxtaposition?
Disproportionately high use of em dashes has been the most conspicuous giveaway for LLM-generated text for some time now. Once this became widespread knowledge, people began to consciously seek it out and edit it from their responses to seem human.
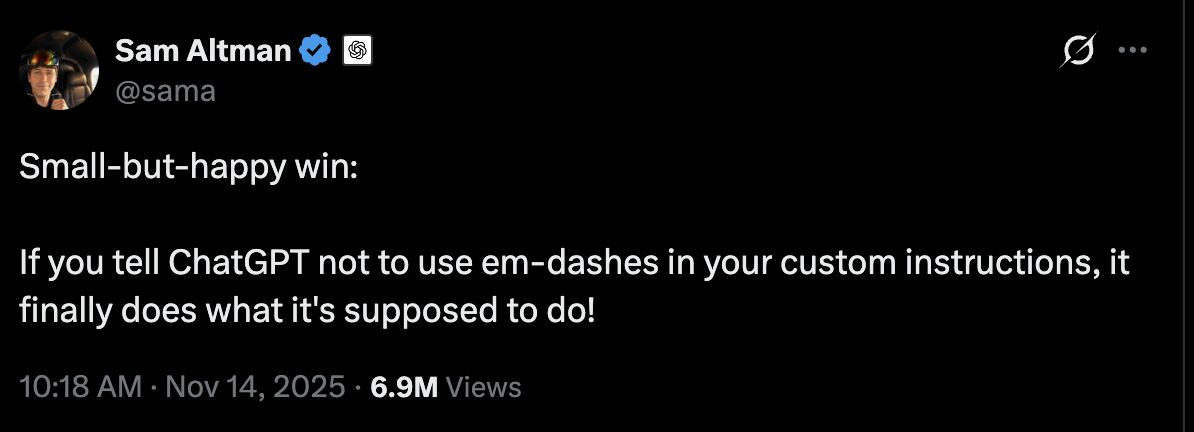
Even foundational model labs took note and implemented product changes.
Over time, LLMs have started to exhibit other idiosyncratic elements which do make the text feel AI-generated, but are hard to put a finger on. One such element is the widespread use of corrective juxtaposition.
This is a figure of self-correction, where the LLM proposes one formulation, rejects it, and substitutes a sharper one.
Some examples from LinkedIn posts where it is found in particularly high numbers:
“You aren’t struggling because your appraisal was bad. You are struggling because you are the most convenient target in the financial ecosystem.”
“AI adoption is no longer the differentiator. Workflow ownership is.”
“You don’t lose PM job offers because you lack skills. You lose them because you can’t explain your own projects and skills clearly.”
I wanted to understand why this is so common. What prompts the LLM to do so?
The research on LLM linguistics is not as strong, but I came across two papers that try to pin this down. A 2026 paper, “The Last Fingerprint”, argues that the em dash is markdown leaking into prose. LLMs train on markdown-saturated sources (GitHub, Stack Overflow, Reddit), internalise dashes as structural joints, and when instructed to write prose, the em dash survives suppression because it is already prose-legal.
The 2024 “Why Does ChatGPT ‘Delve’ So Much?” paper takes the lexical version of the same question. Its authors rule out:
-
Training data
-
Fine-tuning data
-
Model architecture
-
Algorithmic choices
The only positive signal points to Reinforcement Learning from Human Feedback (RLHF). Human evaluators who are believed to be rushed, underpaid, and technical, reward outputs that use certain words and structures, and the model learns to reach for them. Both papers converge on the same culprit. RLHF amplifies latent tendencies installed during training, turning them into the stylistic fingerprints we now recognise.
This made me inclined to believe that corrective juxtaposition is also a post-training consequence. Here are the notes from my research:
1. LLMs are designed to reduce cross-entropy loss
An LLM is autocomplete. Given a stretch of text, it outputs a probability distribution over the next token, samples one, appends it, and repeats. It is shown an enormous pile of human writing and asked, billions of times, to guess what comes next.
Every guess the model makes subtly rewires its internal connections based on how accurate it was. The score it is graded on is called cross-entropy loss. A lower score indicates low surprise, which in turn means good prediction.
2. Pre-training influence
During this phase, the model is absorbing information from different internet genres: Reddit debates, Stack Overflow, technical documentation, corporate op-eds, and academic papers. Across all these disparate sources, corrective juxtaposition repeatedly appears as a standard tool for clarification and persuasion.
By seeing this “Not X, but Y” pivot successfully deployed across so many different contexts, the model learns that it is a highly valid, statistically smooth rhetorical structure. Pre-training wires this construction into the model’s fundamental vocabulary.
At the opening of a sentence, the context is thin, the entropy over the next token is enormous, and committing to a negation should look arbitrary. Two pressures pre-warm the first few tokens.
First, responses with corrective juxtaposition are common when prompts carry implicit latent polarity. A question of the form “why does this happen” sits squarely in the semantic neighbourhood of explanation, critique, and tradeoff, and those genres are saturated with contrastive prose in the pre-training data.
Second, long-form explanations with discourse organisers such as however, but, while, etc., are extremely frequent in pre-training data. LLMs gravitate towards emitting these words to collapse the plausible continuations into a narrower rhetorical trajectory.
3. Post-training reinforcement
Corrective juxtaposition is a near-perfect shortcut for an AI. It is computationally cheap to generate, structurally obvious, and compresses the appearance of insight efficiently.
During the post-training phases (Supervised Fine-Tuning (SFT) and RLHF), human annotators grade model outputs. If a rushed, skim-reading grader even slightly favours a response that cleverly uses corrective juxtaposition over one that states the answer plainly, the reward model learns to chase that preference.
Over millions of optimisation steps, these small human preferences can narrow the stylistic distribution of the model’s outputs. Structures that reliably signal clarity or insight to annotators become disproportionately reinforced, even when they add little semantic value.
Once it adopts this strategy, the mechanics of text generation lock in. As soon as the model commits to a negation at the start of a sentence (e.g., “It’s not that…”), the probability space for the next few words narrows drastically. The underlying statistics strongly constrain the continuation space.
A stylistic signal used to be a reliable proxy for human thought. LLMs commoditise the signal without commoditising the underlying thing.
A large and growing share of the internet in 2026 is now drafted or polished by LLMs. This text will be scraped into the next generation of pre-training data. So a tic that originated as a post-training artefact, amplified by reward-model shortcut bias, is spreading across the open web by users treating model output as their own voice. Until something changes in the training approach, these idiosyncrasies will become genuinely abundant in the base data and further nudge models to reinforce this behaviour.