Why Google might win? (1/5)
In Capital theory of AI, I argued that the AI progress is a capital allocation problem. Scale purchases capability. The winners will be those with massive capital to meet the compute scaling demands, or companies that sit on specific data moats.
While listening to this amazing Acquired episode on “Google: The AI Company”, I realised that my framing was a slight oversimplification of what the AI value chain looks like.
My revised hypothesis is that it is a 5-layer structure:
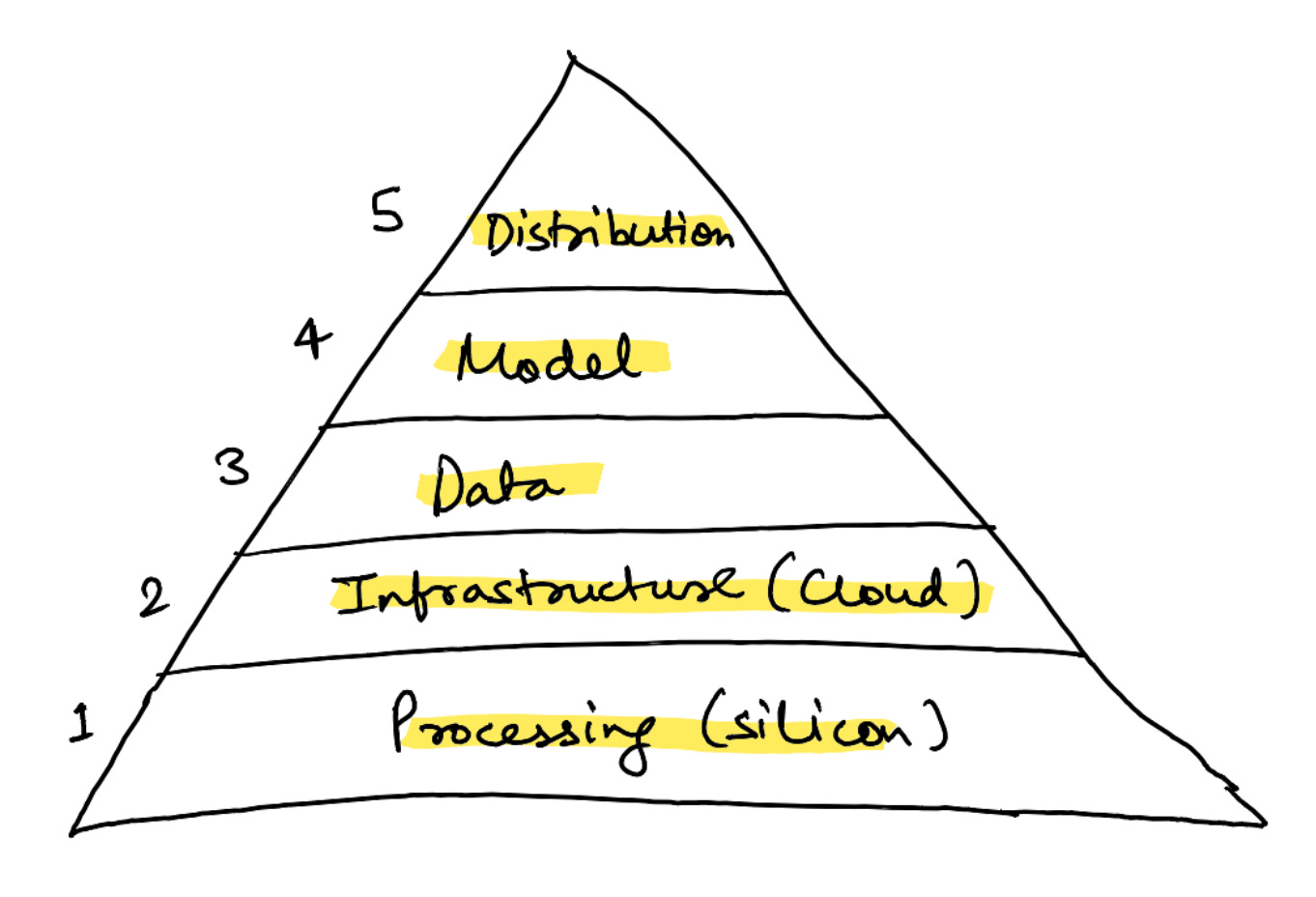
Google has strengths across all 5 layers, and that might be why it wins the AI race in the short/medium-term12.
- Silicon: custom TPU (tensor processing unit) chips
- Infrastructure: Private fibre and cloud connecting those chips
- Data: YouTube, Search, Maps, Scholar
- Model: Gemini, built on cost-effective self-owned hardware
- Distribution: Consumer apps spanning almost all touchpoints of human experience
The strategic logic is different at every level. This series examines each layer. I’m starting with silicon because it sits at the bottom of the stack, and because it’s where the most underappreciated battle is playing out.
For decades, AI ran on CPUs–general-purpose processors that handle instructions one at a time.
It was only 2012 when Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton figured that the GPUs (traditionally used for rendering video game graphics) could be leveraged for training image recognition models due to the similarities in inherent computation (both required matrix multiplications).
Today, every major AI lab runs on Nvidia GPUs. OpenAI trains on Microsoft Azure’s Nvidia clusters. Meta assembled over 350,000 H100 GPUs to train Llama 4. xAI built the Colossus cluster with 200,000+ H100 and H200 GPUs.
Google took a different path. As early as 2013, they realised that given the scale of their consumer apps, relying solely on Nvidia could potentially mean buying their entire production. So, they started building their own processors–TPUs.
TPUs are purpose-built for AI math, which makes them more efficient but less flexible than Nvidia’s GPUs. This enables a unique margin structure.
Nvidia designs and sells complete chips. It controls the full stack from architecture to software ecosystem (CUDA), and prices accordingly (leading to roughly 80% gross margins).
Google’s arrangement is different. It designs the chip logic–what the chip should do, how data flows through it. Broadcom then takes that design and turns it into something that can actually be fabricated–physical transistor layouts, memory interfaces, power delivery. TSMC manufactures the final product.
Google pays Broadcom a ~50% margin for this value-added. Still significant, but it is reasonably lower than what Nvidia charges for the whole package.
When chips represent over half of data centre cost, that margin gap is a structural cost advantage on every token that Google serves. Consequently, Gemini’s API pricing is cheaper than OpenAI’s equivalent models.
The clearest validation of this cost advantage comes from an unlikely source. Last October, Anthropic–arguably Google’s most direct competitor in frontier models–signed a cloud deal for up to one million TPU chips worth tens of billions of dollars. This is a commercial agreement: Anthropic pays for TPU compute through Google Cloud. It is separate from Google’s $2 billion equity investment in the company.
This is why silicon is the foundation of Google’s AI stack. AI runs at roughly 50% gross margins, considerably lower than Search’s 89%. At those margins, having low-cost compute is almost existential. And right now, no one produces it cheaper than Google.
-
Winning the AI race in itself doesn’t guarantee profits or long-term market dominance. The current ways of experiencing AI are at odds with Google’s dominant search business–it remains to be seen how things progress, and how Google adjusts/makes up for the alternative reality. ↩
-
Structural advantage doesn’t guarantee dominance. The biggest counterforces that Google faces are organisational drag, the innovator’s dilemma, and the risk that AI would never monetise as effectively as Search. But Google has navigated well through this over the last couple of years. Pichai merged DeepMind and Google Brain–a seemingly difficult task given the circumstances of the DeepMind acquisition. And Sergey Brin returned to work on Gemini. ↩